前言
本文为个人学习笔记整理,行文较为随性,未尽完善之处,敬请谅解。
Abstract
Task
Copyright issues related to Diffusion Models (DMs)
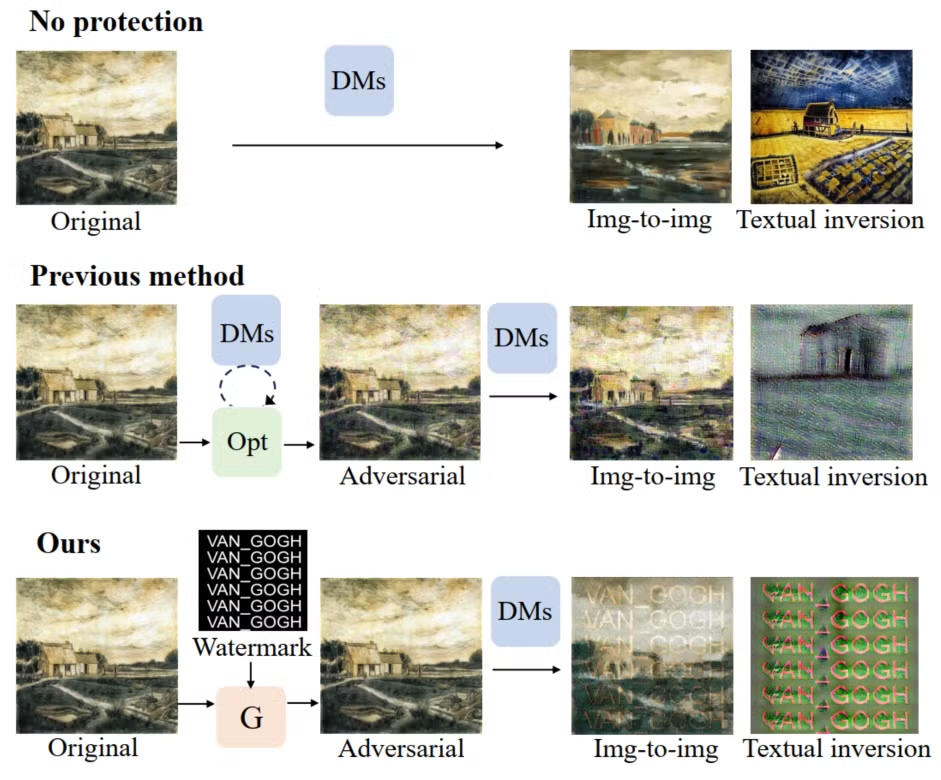
Technical challenge for previous methods
There don’t seem to be any established methods for adding visible watermarks on the generated images. Instead, most current approaches focus on adding perturbations, such as adversarial examples, to the original images to prevent diffusion models from imitating unauthorized images.
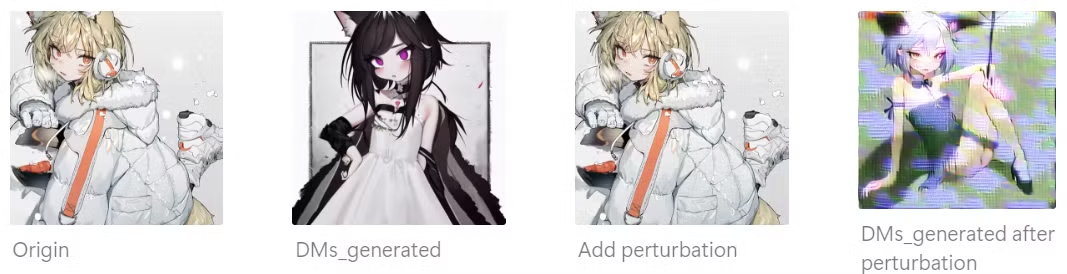
Key Insight/Motivation
- They adds visible watermarks on the generated images
- which is a more straightforward way to indicate copyright violations? —— I agree
Technical contributions
- Using a generator instead of the original diffusion model
- Benefit: High computation and memory requirements, lower to 0.2s per image after the generator is trained (Diff-protect needs 8G30S per image on ? GPU)
- NVIDIA A100 80GB GPU, Training the generator using 100 samples with 200 epochs takes about 20 minutes? —— maybe, more like a better trade-off
- Benefit: High computation and memory requirements, lower to 0.2s per image after the generator is trained (Diff-protect needs 8G30S per image on ? GPU)
- Good transferability across unknown generative models
- Benefit: A more effective approach to copyright protection
- Is it difficult for attackers to remove the perturbations? —— Didn’t OpenSource
- Benefit: A more effective approach to copyright protection
Introdution
Task and application
potential copyright violations when unauthorized images are used to train DMs or to generate new creations by DMs.
For example, an entity could use copyrighted paintings shared on the Internet to generate images with a similar style and appearance, potentially earning illegal revenue.
Technical challenge for previous methods
- Technical challenge 1
- Previous method
- Watermark ------ From: https://www.mihuashi.com/artworks/5827524

- Failure cases (Limitation)
- visiable & DMs may ignore the waterrmark
- Technical reason
- Costly & Need special design for each paintings
- Watermark ------ From: https://www.mihuashi.com/artworks/5827524
- Previous method
- Technical challenge 2
- Previous method
- Failure cases (Limitation)
- they are primarily designed to protect the copyright of DMs or to distinguish generated images from natural ones, which differs from our goal of protecting the copyright of human creations.
- Succeed in their task (Totally white-box attack)
- Technical reason
- Costly and Not practical
- Technical challenge 3
- Previous method

- Failure cases (Limitation)
- Difficult to comprehend (add chaotic textures to the generated images)
- The original image’s copyright is not traceable
- Technical reason
- Easy to remove (Not included in the original paper)
- Time-consuming (Each AdvE need to be optimized separately & iterative optimization)
- Previous method
Introdution of the challenges and pipelines
- key innovation/insight/contribution
- Force DMs to generate images with visible watermarks as well as chaotic textures.
- contribution 1
- Creat a novel framework that embeds personal watermarks into the generation of adversarial examples to prevent copyright violations caused by DM-based imitation.
- advantage/insight
- Force DMs to generate images with visible watermarks for tracing copyright.
- contribution 2
- Design three losses: adversarial loss, GAN loss, and weighted perturbation loss
- advantage/insight: ---
- contribution 3
- Experiments shows that the method is robustness and have the transferability to other models
- advantage/insight: ---
Demos/applications

Method
overview
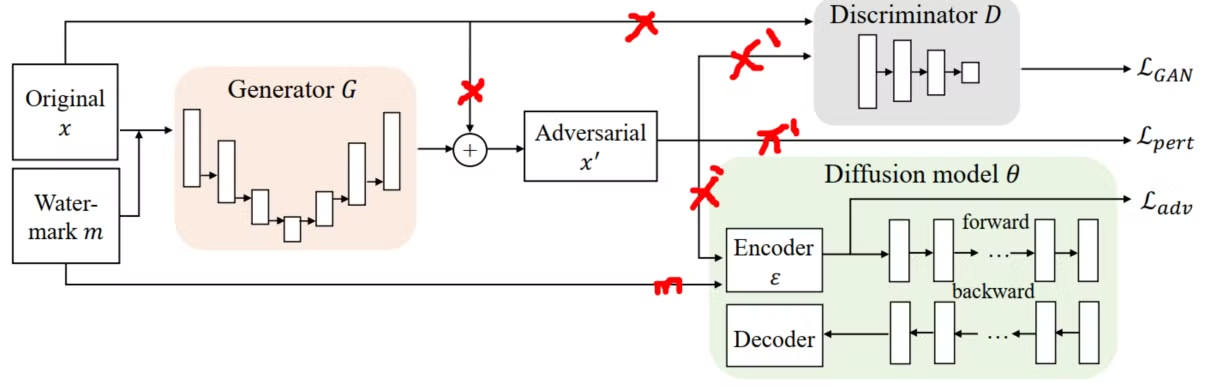
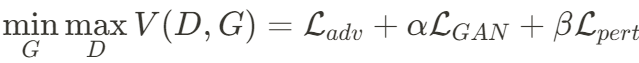
Task Overview
- Input(What we have): Original x ( 100+ samples from artist ), diffusion model
- Output: Adversarial x'
Modules Overview


Pipeline module 1
- Motivation
- How to do
- Why it works?
- technical advantage
Pipeline module 2
- Motivation
- How to do
- Why it works?
- technical advantage
Pipeline module 3
- Motivation
- For transferability
- LDMs are more common in practice (efficiency & high-quality)
- How to do
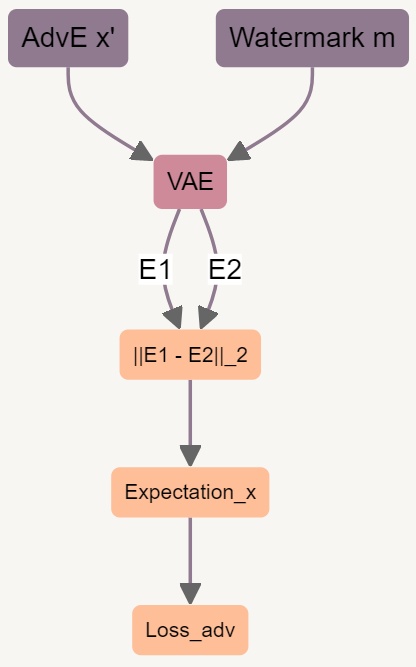
- Why it works?
Use a loss to constrain the x' to resemble the watermark m, simple but work - technical advantage
- No need to attack the U-Net to produce satisfactory results, faster
Experiments
Comparision experiment
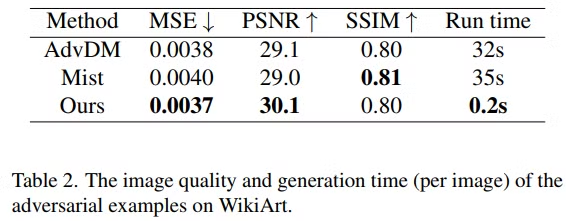
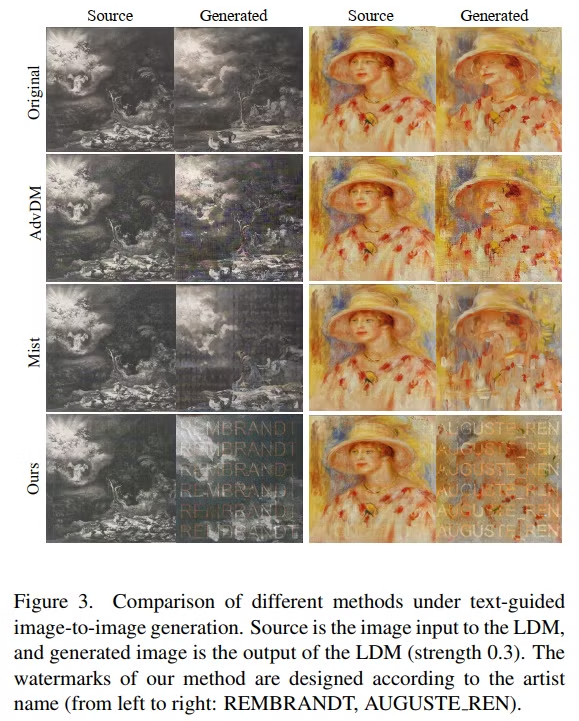
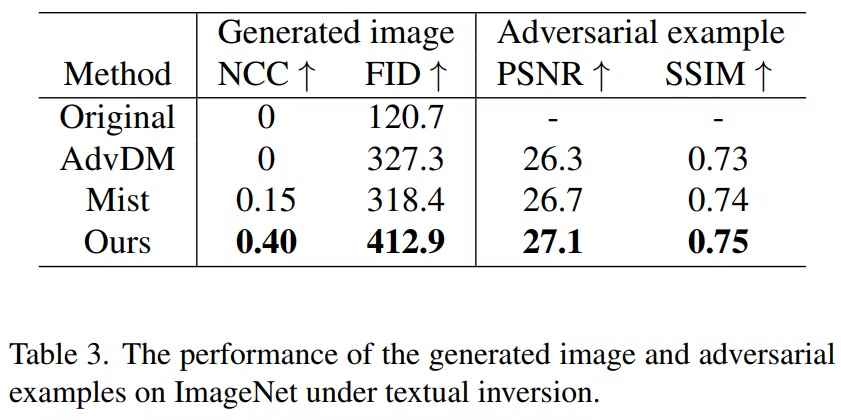
Ablation studies
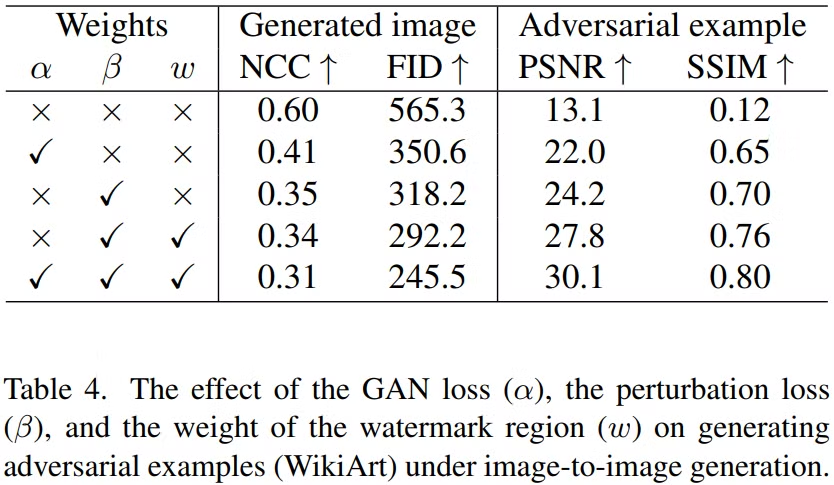
- Core contribution to performance
- Main components to performance
Reference
| Title | Authors | Year | Citations | References | Similarityto origin |
|---|---|---|---|---|---|
| GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models | Shawn Shan, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, Ben Y. Zhao | 2023 | 116 | 131 | 18.3 |
| The Stable Signature: Rooting Watermarks in Latent Diffusion Models | Pierre Fernandez, Guillaume Couairon, Herv'e J'egou, Matthijs Douze, T. Furon | 2023 | 87 | 106 | 17.5 |
| A Recipe for Watermarking Diffusion Models | Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Ngai-Man Cheung, Min Lin | 2023 | 66 | 81 | 16.6 |
| Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples | Chumeng Liang, Xiaoyu Wu, Yang Hua, Jiaru Zhang, Yiming Xue, Tao Song, Zhengui Xue, Ruhui Ma, Haibing Guan | 2023 | 65 | 66 | 24.6 |
| Raising the Cost of Malicious AI-Powered Image Editing | Hadi Salman, Alaa Khaddaj, Guillaume Leclerc, Andrew Ilyas, A. Madry | 2023 | 65 | 56 | 19.1 |
| End-to-End Diffusion Latent Optimization Improves Classifier Guidance | Bram Wallace, Akash Gokul, Stefano Ermon, N. Naik | 2023 | 53 | 55 | 16.8 |
| Anti-DreamBooth: Protecting users from personalized text-to-image synthesis | T. Le, Hao Phung, Thuan Hoang Nguyen, Quan Dao, Ngoc N. Tran, A. Tran | 2023 | 47 | 67 | 18.8 |
| SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions | Yuseung Lee, Kunho Kim, Hyunjin Kim, Minhyuk Sung | 2023 | 38 | 55 | 15.9 |
| DiffusionShield: A Watermark for Copyright Protection against Generative Diffusion Models | Yingqian Cui, J. Ren, Han Xu, Pengfei He, Hui Liu, Lichao Sun, Jiliang Tang | 2023 | 35 | 47 | 19.2 |
| Mist: Towards Improved Adversarial Examples for Diffusion Models | Chumeng Liang, Xiaoyu Wu | 2023 | 24 | 13 | 19.7 |
| FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition | Sicheng Mo, Fangzhou Mu, Kuan Heng Lin, Yanli Liu, Bochen Guan, Yin Li, Bolei Zhou | 2023 | 20 | 59 | 16.8 |
| Unlearnable Examples for Diffusion Models: Protect Data from Unauthorized Exploitation | Zhengyue Zhao, Jinhao Duan, Xingui Hu, Kaidi Xu, Chenan Wang, Rui Zhang, Zidong Du, Qi Guo, Yunji Chen | 2023 | 18 | 45 | 17.5 |
| The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing | Shen Nie, Hanzhong Guo, Cheng Lu, Yuhao Zhou, Chenyu Zheng, Chongxuan Li | 2023 | 18 | 80 | 16.6 |
| Generative Watermarking Against Unauthorized Subject-Driven Image Synthesis | Y. Ma, Zhengyu Zhao, Xinlei He, Zheng Li, M. Backes, Yang Zhang | 2023 | 17 | 69 | 19.5 |
| Copyright Protection in Generative AI: A Technical Perspective | Jie Ren, Han Xu, Pengfei He, Yingqian Cui, Shenglai Zeng, Jiankun Zhang, Hongzhi Wen, Jiayuan Ding, Hui Liu, Yi Chang, Jiliang Tang | 2024 | 15 | 178 | 17.7 |
| Toward effective protection against diffusion based mimicry through score distillation | Haotian Xue, Chumeng Liang, Xiaoyu Wu, Yongxin Chen | 2023 | 14 | 40 | 18.3 |
| Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers | Chi-Pin Huang, Kai-Po Chang, Chung-Ting Tsai, Yung-Hsuan Lai, Yu-Chiang Frank Wang | 2023 | 13 | 57 | 18.6 |
| Improving Adversarial Attacks on Latent Diffusion Model | Boyang Zheng, Chumeng Liang, Xiaoyu Wu, Yan Liu | 2023 | 13 | 40 | 16.7 |
| FT-Shield: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models | Yingqian Cui, Jie Ren, Yuping Lin, Han Xu, Pengfei He, Yue Xing, Wenqi Fan, Hui Liu, Jiliang Tang | 2023 | 9 | 35 | 19.6 |
| Enhanced Controllability of Diffusion Models via Feature Disentanglement and Realism-Enhanced Sampling Methods | Wonwoong Cho, Hareesh Ravi, Midhun Harikumar, V. Khuc, Krishna Kumar Singh, Jingwan Lu, David I. Inouye, Ajinkya Kale | 2023 | 6 | 52 | 16.8 |
| Toward Robust Imperceptible Perturbation against Unauthorized Text-to-image Diffusion-based Synthesis | Yixin Liu, Chenrui Fan, Yutong Dai, Xun Chen, Pan Zhou, Lichao Sun | 2023 | 6 | 53 | 16.5 |
| Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework | Ruijia Wu, Yuhang Wang, Huafeng Shi, Zhipeng Yu, Yichao Wu, Ding Liang | 2023 | 6 | 47 | 16.4 |
| IMMA: Immunizing text-to-image Models against Malicious Adaptation | Yijia Zheng, Raymond A. Yeh | 2023 | 5 | 52 | 18.7 |
| Watermark-embedded Adversarial Examples for Copyright Protection against Diffusion Models | Peifei Zhu, Tsubasa Takahashi, Hirokatsu Kataoka | 2024 | 4 | 66 | 100 |
| Catch You Everything Everywhere: Guarding Textual Inversion via Concept Watermarking | Weitao Feng, Jiyan He, Jie Zhang, Tianwei Zhang, Wenbo Zhou, Weiming Zhang, Neng H. Yu | 2023 | 4 | 54 | 22 |
| Perturbing Attention Gives You More Bang for the Buck: Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models | Jingyao Xu, Yuetong Lu, Yandong Li, Siyang Lu, Dongdong Wang, Xiang Wei | 2024 | 3 | 36 | 21.4 |
| Imperceptible Protection against Style Imitation from Diffusion Models | Namhyuk Ahn, Wonhyuk Ahn, Kiyoon Yoo, Daesik Kim, Seung-Hun Nam | 2024 | 3 | 70 | 20.4 |
| R.A.C.E.: Robust Adversarial Concept Erasure for Secure Text-to-Image Diffusion Model | C. Kim, Kyle Min, Yezhou Yang | 2024 | 3 | 74 | 18.2 |
| Pick-and-Draw: Training-free Semantic Guidance for Text-to-Image Personalization | Henglei Lv, Jiayu Xiao, Liang Li, Qingming Huang | 2024 | 3 | 33 | 16 |
| Pruning for Robust Concept Erasing in Diffusion Models | Tianyun Yang, Juan Cao, Chang Xu | 2024 | 2 | 40 | 22.9 |
| A Somewhat Robust Image Watermark against Diffusion-based Editing Models | Mingtian Tan, Tianhao Wang, Somesh Jha | 2023 | 2 | 66 | 22.5 |
| Pixel is a Barrier: Diffusion Models Are More Adversarially Robust Than We Think | Haotian Xue, Yongxin Chen | 2024 | 2 | 49 | 21.3 |
| Towards Test-Time Refusals via Concept Negation | Peiran Dong, Song Guo, Junxiao Wang, Bingjie Wang, Jiewei Zhang, Ziming Liu | 2023 | 2 | 35 | 18.8 |
| Towards Memorization-Free Diffusion Models | Chen Chen, Daochang Liu, Chang Xu | 2024 | 2 | 39 | 17.1 |
| VA3: Virtually Assured Amplification Attack on Probabilistic Copyright Protection for Text-to-Image Generative Models | Xiang Li, Qianli Shen, Kenji Kawaguchi | 2023 | 2 | 59 | 16.6 |
| PiGW: A Plug-in Generative Watermarking Framework | Rui Ma, Mengxi Guo, Yuming Li, Hengyuan Zhang, Cong Ma, Yuan Li, Xiaodong Xie, Shanghang Zhang | 2024 | 1 | 53 | 18.9 |
| Privacy-Preserving Low-Rank Adaptation for Latent Diffusion Models | Zihao Luo, Xilie Xu, Feng Liu, Yun Sing Koh, Di Wang, Jingfeng Zhang | 2024 | 1 | 43 | 18 |
| SimAC: A Simple Anti-Customization Method for Protecting Face Privacy against Text-to-Image Synthesis of Diffusion Models | Feifei Wang, Zhentao Tan, Tianyi Wei, Yue Wu, Qidong Huang | 2023 | 1 | 39 | 17.1 |
| Prompt-Agnostic Adversarial Perturbation for Customized Diffusion Models | Cong Wan, Yuhang He, Xiang Song, Yihong Gong | 2024 | 0 | 63 | 20 |
| PaRa: Personalizing Text-to-Image Diffusion via Parameter Rank Reduction | Shangyu Chen, Zizheng Pan, Jianfei Cai, Dinh Q. Phung | 2024 | 0 | 42 | 16.6 |
| PID: Prompt-Independent Data Protection Against Latent Diffusion Models | Ang Li, Yichuan Mo, Mingjie Li, Yisen Wang | 2024 | 0 | 51 | 16.6 |